Mappstruktur, filnamn och versionering
- Mappstruktur
- Filnamn
- Versionering med filnamn
- Spårbarhet (proveniens)
- Versionskontroll
- Programmatisk versionshantering
Mappstruktur
En genomtänkt mappstruktur är en förutsättning för ett välorganiserat forskningsmaterial. Det bör därför finnas en mappstruktur på plats redan när data börjar samlas in, med begripliga mappnamn och en tydlig utformning.
Det är bra om forskningsprojektets filer är organiserade i mappar med namn som säger något även för den som inte är så insatt i projektet – till exempel en ny medarbetare eller en intressent som vill se vad som händer i projektet.
Mappar bör:
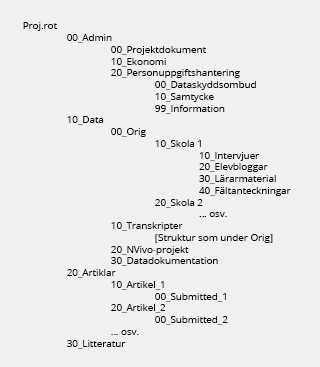
- följa en struktur med mappar och undermappar som motsvarar projektarbetets upplägg och arbetsflöde
- ha självförklarande namn som inte är längre än nödvändigt
- ha unika namn – undvik att ge samma namn till både en mapp och en undermapp.
Mappstrukturen gör det överskådligt för alla inblandade vad som finns var, och den ger en mall för hur man sparar och organiserar data inom projektet. Om data samlas in i omgångar kan mappar skapas för varje insamlingsomgång, med enhetliga namn på vad som samlas in, insamlingskontext och datum.
Ett tips är att i den översta mappen i mappstrukturen lägga en fil i .txt-format (en så kallad ReadMe-fil) som beskriver strukturen och hur du har valt att tänka även kring filnamn och versionering. Om du senare behöver ändra på mappstrukturen så dokumenterar du detta här.
Filnamn
Det kan snabbt bli många filer i ett forskningsprojekt så bestäm i förväg hur filerna ska namnges. På så sätt underlättas arbetet under insamling och databehandling och det blir lättare att hitta filer i mappstrukturen. Detta gäller inte minst om det är flera personer som skapar och namnger filer.
Ett filnamn bör:
- vara unikt inte bara i sin egen mapp utan helst i hela projektet. Råkar en fil trilla ur sin mapp så ska man av filnamnet veta till vilken mapp den hör
- ge en uppfattning om innehållet
- vara ganska kort
- ha versionsnumret direkt i namnet.
Versionering med filnamn
Forskningsarbete kräver ofta modifiering av datafiler, ibland flera gånger. Efter att data har samlats in måste de rensas och bearbetas tills den slutliga datamängden skapas.
Det enklaste sättet att spåra sådana ändringar är att skapa "versioner" (lokala arbetskopior) av datafilerna. Det betyder att datafilerna inte ändras, utan att resultaten av successiva bearbetningar sparas som nya filer. Den ursprungliga versionen av data är vanligtvis från datainsamlingen och varje ny sparad version av data får ett nytt versionsnummer (till exempel v01, v02, v03) eller är märkt med datumet (ISO-format, t.ex. 2023-08-28) för filens skapande. Med en praxis för namngivning av filversioner kan du enkelt hitta den senaste versionen av en datafil, dokumentera de olika versionerna och förstå var en viss fil finns i arbetsflödet.
Exempel:
Tänk dig att du har följande datafiler i ett projekt:
- PeterS_ordlista_17jun.wav
- talare1_ord_slutlig.wav
- talare1_slutlig2.wav
- talarePS_ord_ren.wav
Vad ser du här? I vilken ordning har filerna samlats in? Vad innehåller de? Hur förhåller de sig till varandra? Är Peter S. samma person som talare 1?
Antag att filerna i stället namnges på följande sätt:
- talare1_ordlista_v00_orig.wav
- talare1_ordlista_v01_ren.wav
- talare1_ordlista_v02_ren.wav
- talare1_ordlista_v03_ren_slutlig.wav
eller som:
- talare1_ordlista_2023-03-11_orig.wav
- talare1_ordlista_2023-03-15_ren.wav
- talare1_ordlista_2023-03-15_ren_v2.wav
- talare1_ordlista_2023-03-16_ren_slutlig.wav
Då ser du att samtliga filer innehåller talare 1:s läsning av en ordlista. Filerna är versioner av varandra: originalfilen ligger överst och de andra är rensade versioner av denna, med den slutliga versionen nederst.
Spårbarhet (proveniens)
Proveniens är dokumentationen av ett dataobjekts ursprung och historia. Genom att föra en logg över ändringar, där du dokumenterar när och hur varje filversion skapades, säkerställer du att du kan redogöra för vad som har gjorts med materialet om någon senare ifrågasätter projektets data eller slutsatser, eller om du själv måste backa och modifiera analyskedjan.
Att dokumentera när varje filversion var färdig gör det dessutom enklare att återställa filer från säkerhetskopiering – till exempel genom att återställa en tidigare version av en OneDrive-fil.
Versionskontroll
System för versionskontroll erbjuder ett mer sofistikerat sätt att hantera versioner av data. Versionskontroll innebär att du arbetar mot ett centralt lager där alla förändringar sammanställs. Varje ändring av en datafil dokumenteras och ändringar i flera filer kan paketeras tillsammans. Flera användare kan samarbeta om att ändra filer, med möjlighet att slå samman samtidiga ändringar och lösa eventuella överlappningar. Användare kan också skapa lokala kopior och testa ändringar.
Vanliga öppna verktyg för versionskontroll av källkod och textbaserade datafiler (.txt, .csv, .md) är Git och Subversion. Versionskontroll av programspecifika filer (till exempel .xlxs) kan kräva en kommersiell lösning.
Molnbaserade plattformar som erbjuder kodlagring och samarbetsverktyg är till exempel GitHub, BitBucket, och GitLab. Kodlagret kan också bevaras lokalt på din egen dator eller under en Git/Subversion på servrar som används i din forskargrupp.
Programmatisk versionshantering
Ett alternativ till versionshantering med filnamn är att skapa ett skript eller en körbar fil som läser originalfilen och modifierar data. Detta är en vanlig metod för statistiska analysapplikationer som STATA, R och SAS.
Du bör dokumentera din kod noggrant, så att andra användare kan förstå bearbetningsstegen. Du kan också publicera skriptet tillsammans med data. Observera att vissa högt rankade tidskrifter kräver att analyskoden görs tillgänglig.
Tips!
När du startar ett projekt, tänk på att:
- bestämma vilka riktlinjer för versioneringen, mappstrukturen och filnamngivningen som gäller i projektet
- ge en person ansvar för att riktlinjerna för namngivning och versionering följs
- uppdatera vid behov och dokumentera förändringarna.