Text som forskningsdata

Text är en mycket vanlig form av forskningsdata. Text förbli ett av våra främsta sätt att förmedla information till varandra som människor. Särskilt vanligt är det kanske att humanister forskar på text, men en klassisk textgenre, intervjun, används inom samhällsvetenskaplig, medicinsk, ekonomisk, konstnärlig och IT-relaterad forskning.
På den här sidan hittar du information om vad som gäller för textbaserad forskning. Först kommer fyra fallstudier av textbaserad forskning och forskningsnära verksamhet. Fallstudierna bygger på intervjuer med forskare och personal på några olika institutioner som arbetar mycket med text. Fallstudierna presenteras dels som text, dels i videoformat. Det är samma information i båda de två formaten. Efter fallstudierna följer en genomgång av premisserna för metadata när det gäller textbaserad forskning. Längst ner på sidan finns kompletterande information om format och datatyper och programvaror, utöver de som nämns i fallstudierna.
Fallstudier
De fyra fallstudierna rör forskning där text är den grundläggande forskningsdatan. Fallstudierna kommer från olika forskningsområden och rör olika slags studier, med skiftande mål och metoder. Därför kan forskningsdata från de olika fallstudierna se väldigt olika ut, och de ställer olika krav när det gäller kureringen.
Fall 1: Språkteknologisk textbehandling
Målet med forskning inom språkteknologi är att förenkla och förbättra kommunikationen mellan människor och datorer, samt mellan människor. Språkteknologi innefattar processer och mjukvara som gör att du kan tala in en text i din dator utan att använda tangentbordet, att din text kan bli automatiskt språkrättad av datorn. Du kan också föra ett samtal med en person som talar ett annat språk, tack vare automatiska översättningar. Språkteknologi handlar om att ta fram verktyg för t.ex. maskinöversättning, taligenkänning, textanalys, talsyntes och elektroniska lexikon.
Forskare som arbetar med språkteknologi har ofta omfattande programmeringskunskaper. Har man inte sådana kunskaper i bagaget kan man med fördel använda sig av de redskap som görs tillgängliga av t.ex. Nationella språkbanken.
Metoden i den specifika fallstudien går ut på att omvandla människoläsbar text till mer maskinvänliga format, till exempel tabeller eller XML-format. Eftersom det ofta handlar om stora textmängder tränar man datorer att göra det här automatiskt. Programvaror av slaget OCR (Optical Character Recognition) kan göra handskriven text maskinläsbar och kan på så vis digitisera materialet. När texterna blivit digitiserade och uppmärkta går det att göra avancerade analyser av materialet, t.ex i form av konkordanstabeller.

Kurering
Språkteknologiska studier är ofta avhängiga av specialiserad forskningsmjukvara. Sådan mjukvara är ofta utvecklad vid universitet eller forskningsinstitut, snarare än stora mjukvaruföretag. Eftersom syftet med mjukvaran är forskning ligger fokus ofta på funktionalitet snarare än användarvänlighet. Ibland kan programkoden delas via t.ex. GitHub, men inte alltid, och även om programmen är tillgängliga nu är det inte säkert att de är det för all framtid. I idealfallet bör datan därför levereras tillsammans med verktyget eller åtminstone med instruktioner för att bygga ett verktyg som kan hantera datan.
Dataformaten är ofta öppna format, och är oftast inte heller jättesvåra att förstå. Ofta använder forskarna vedertagna standarder, som Text Encoding Initiative och ISO-639 för språk (se mer nedan) eller Universal Dependencies för uppmärkning av syntaktiska relationer.
Uppmärkningen av data är helt central information att bevara. Information om hur uppmärkningen gått till är därför avgörande för att kunna bedöma hur bra datan är eller hur bra den lämpar sig till ett visst ändamål. Man bör se till att ange vilka standarder man följer, men också vilka tekniker som använts för att göra uppmärkningen.
Fall 2: Jämföra afrikanska språk
Jämförande studier av språk handlar om att se hur lika eller olika språk är. Forskningen kan utgå från tryckta texter, eller från språkligt material som samlas in genom intervjuer med talare av olika språk. Forskningen kan fokusera på enskilda ord och deras uttal, eller på grammatiska konstruktioner i språket.
Metoden som används i denna fallstudie innefattar att samla in information genom att be uppgiftslämnarna översätta ett antal valda exempelmeningar till sitt eget språk, och även förklara varför de väljer ett visst ord eller en viss ordföljd i ett specifikt sammanhang. Detta kallas detta ”elicitering”, det vill säga forskaren framkallar ett visst innehåll från sina uppgiftslämnare.
Materialet kan bestå av tusentals meningar, som sedan måste märkas upp för att forskaren lättare ska kunna hitta intressanta aspekter i datan. Meningarna transkriberas till text, och datan märks sedan upp med information för varje enskilt ord, t.ex. om morfologi, semantik m.m. I den färdiga filen kan forskaren sedan filtrera fram meningar med komplexa kombinationer av kriterier genom att importera Excelfilen till programmet OpenRefine (se mer nedan).
Kurering
Eftersom datan ofta är tabellbaserad är det lätt att spara allting som TSV. Excelfilerna kan också innehålla metadata, inlagda med hjälp av insticksmodulen Colectica for Excel. Den informationen sparas genom att använda Colectica for Excels funktion för att skapa en PDF-kodbok.
Det kan också finnas metadata utanför själva datafilen. Sådan information kan handla om uppgiftslämnarna och förklara var de är uppvuxna, deras socioekonomiska bakgrund, föräldrarnas modersmål m.m. Detta är information som är viktig för att avgöra om en talare är en pålitlig källa för språket eller inte, vilket kan vara avgörande om två talare uttrycker samma betydelse på två olika sätt. Det är också värdefullt att ha med information om hur och när datainsamlingen gått till, hur talarna valts ut, och så vidare.
Fall 3: Fjärrläsning
Fjärrläsning handlar om att analysera stora mängder text, historiska eller skönlitterära källor. Motsatsen till fjärrläsning är närläsning, det vill säga att läsa en bok eller ett verk på nära håll, och analysera texten på djupet. Vid fjärrläsning tar forskaren ett steg bort från texten och söker efter mönster i stora mängder litteratur samtidigt, till exempel för att jämföra olika författare eller genrer eller tidsperioder med. Fjärrläsning kan innefatta bland annat:
- text mining, processen att i stora textsamlingar söka efter frekvensen av enskilda ord och hur orden har förändrats över tid. Det går också att studera korrelationer av olika slag, i vilka sammanhang begrepp har använts historiskt (som det avspeglas i de analyserade texterna), vilka ord som tenderar att förekomma nära varandra, och så vidare.
- topic modelling är en benämning på analyser av texters tematiska struktur som bygger på studiet av vilka begrepp som används, i vilka sammanhang de förekommer och hur de relaterar till varandra.
Fjärrläsning med Voyant
I den valda fallstudien använder forskaren webbtjänsten Voyant. Voyant är en kostnadsfri programvara som finns tillgänglig online. Det enda som behövs för att sätta igång är en text eller flera texter som man vill titta på.
I fallstudien analyseras Bram Stokers Dracula från 1897. I huvudgränssnittet i webbtjänsten finns flera olika verktyg samtidigt. Många av verktygen bygger på ordfrekvenser och eftersom de vanligaste orden är ganska ointressanta för de flesta analyser finns det en såkallad stoppordlista där man kan lägga in alla de ord som verktygen ska ignorera. Eftersom språket är engelska innehåller stoppordlistan här ord som a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not osv.
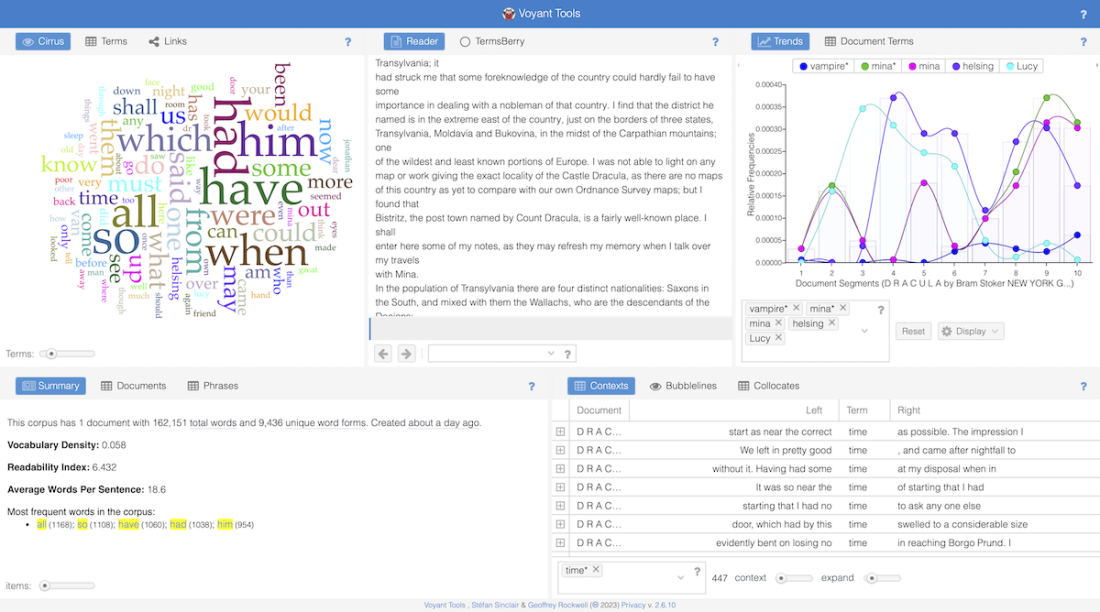
I övre högra hörnet syns verktyget Trends. Det är ett verktyg som visar hur vanliga vissa ord är i olika delar av texten. På x-axeln är texten indelad i tio lika långa avsnitt och på y-axeln syns ordfrekvensen. Både van Helsing och Lucy nämns ganska ofta fram till sjunde tiondelen. Där finns en dipp och efter dippen ökar van Helsing igen samt Mina, men inte Lucy. Ordet ”vampyr” nämns inte alls särskilt ofta i texten, och när det nämns är det nästan uteslutande i andra halvan av texten.
Nedanför Trends syns en konkordansvy där vi kan se i vilka sammanhang ordet ”time” förekommer. Det är ett av textens vanligaste ord. Till vänster syns ett så kallat ordmoln. Ordmolnet är egentligen inget annat än ett färggladare sätt att visa upp en frekvenstabell över de vanligaste orden. Ju större ordet är desto vanligare förekommer det i texten.
Kurering
Webbtjänsten Voyant bryr sig inte om fetstil, typsnitt och liknande formatering. Det är därför nära till hands att spara texten som vanliga txt-filer. Om forskaren arbetar med publicerad litteratur är det inte alltid nödvändigt eller lagligt att tillgänggliggöra hela texterna i sig, utan istället kan det räcka med att ange exakt vilken utgåva som använts, så att någon annan ska kunna upprepa analysen.
Stoppordlistan måste sparas, eftersom den påverkar visualiseringarna. Det är också värt att överväga om vissa av inställningarna i de olika verktygen i Voyant ska sparas, om man vill säkerställa att någon kan upprepa den ursprunliga analysen. Forskare som använder Voyant gör det ofta mer utforskande än strikt analyserande, och det är inte alltid man tänker på att spara varje enskild inställning för sig. Om man vill spara informationen kan man använda den inbyggda exportfunktionen, som gör det möjligt att exportera bland annat en URL som leder tillbaka till exakt samma vy igen. Det är dock inte helt säkert om dessa URL:er är stabila över tid, och det är inte säkert att använda dem ur ett dataarkiveringsperspektiv.
Det finns många andra verktyg som kan användas vid fjärrläsning, som Python och R. Vissa forskare bygger sina egna program eller visualiseringar. Frågor som är vikiga att ställa i samband med kurering av sådan data är t.ex.:
- Hur har materialet kompilerats?
- Vad har exkluderats?
- Hur har man digitaliserat det?
- Vilka är sökparametrarna och vad täcker de inte?
- Kan korpusen åldras och hur kan den i så fall förnyas?
Fall 4: Elevtexter
Denna fallstudie handlar om texter som elever skrivit som en del av sina nationella prov. Den här typen av studier kan göras av forskare som studerar i vilka åldrar barn lär sig olika delar av språket, eller hur den sociala och ekonomiska kontexten påverkar barns språkinlärning, vad invandrade barn har för problem jämfört med barn som vuxit upp i Sverige m.m. Forskare kan också använda den här typen av studier inom pedagogik och läromedelsutveckling, när man utvärderar tidigare prov för att skapa ännu bättre prov framöver. Eftersom målen är blandade blir också metoderna lite olika, men datan kan se ungefär likadan ut ändå.
Elevuppsatser skrivs i regel för hand, och det första steget blir att digitisera uppsatserna. Det kan antingen göras av en person som skriver av texten, eller genom OCR (Optical Character Recognition), för att överföra texten till en digital textfil.

Forskare lägger sedan till metadata i själva textfilen, t.ex. provkoder (som berättar exakt vilket prov eleverna i just det här dokumentet har gjort), ett löpnummer för den specifika eleven, och så vidare. Om materialet är litet kan forskare analysera det för hand, men har forskaren en stor mängd texter behöver man bygga ett verktyg som kan hjälpa till med analysen. Metadata om eleverna samlas också i en Excelfil, där det framgår om eleven gått i kommunal skola eller i privatskola, vilket modersmål eleven har och en del annan information.
Kurering
Den här typen av material kan kureras relativt lätt. Datan ligger i textfiler och metadatan i en Excelfil. För säkerhets skull är det bra att spara allting som ren text, alltså TXT för texten och CSV eller TSV för tabellen.
Däremot bör man granska den kodade informationen i textfilerna och Excelfilen lite extra. Betygssystemet är en sådan sak som kan ändras i framtiden och därför behövs kanske information som förklarar hur systemet såg ut när elevuppsatserna skrevs. I Excelfilen kan man använda Colectica for Excel för att dokumentera vad alla koder står för. Alternativt kan man samla alla koderna med förklaringar i en separat textfil som man levererar tillsammans med datafilerna.
Metadata för textforskning
Text kan användas på så många olika sätt och med många olika syften. Det gör att frågan om metadata kan bli ganska komplicerad. I de intervjuer som gjordes som underlag för fallstudierna nämndes en rad olika typer av objekt som forskarna ansåg vara relevanta i termer av metadata. Beroende på hur forskarna använder sig av text i sitt arbete kan relevanta element ligga på en låg nivå, som ord, meningar eller tecken, eller på en hög nivå, som sidor, texter, filer, eller på en ännu högre nivå, som arkiv och accessioner. Det kan också vara relevant att ge information om de personer som bidragit med information och material till textforskningen, det vill säga uppgiftslämnarna.
Metadata på de lägre nivåerna tenderar att finnas inbakade i själva filerna, exempelvis uppmärkning av ordklasser, satsdelar och liknande. Det är inte metadata som man vill extrahera och spara separat från själva datan. Objekttyper på en hög nivå kan man ibland beskriva utanför själva datafilen, vilket kan göra datan mer lättöverskådlig och eventuellt lättare sökbar. Det kan till exempel gälla metadata om brev som ingår i en samling textdata. Har man information om avsändare, årtal, mottagare och liknande inlagda i en katalogpost för datan tillför man ett mervärde för den som söker efter data, medan information om att breven innehåller substantiv, verb och prepositioner kanske inte tillför så mycket mervärde.
Information som kan vara värdefull för återanvändande av data kan vara t.ex.:- ämne/forskningsområde
- geografisk info
- textens proviniens
- tidsserie
- accessionsnr
- metadata om personer
- metadata om digitaliseringen
- tekniska metadata
- process-metadata
- filernas struktur
- arkiv
- källor för excerpter
- typ av uppteckning och upptecknare
- textkoordinater
- saknade sidor, m.m
Det är bra att i metadatan ange vilken eller vilka objekttyper som är aktuella i de data man beskriver. De olika objekttyperna ställer dock olika krav på beskrivningen, och de mångsidiga användningsområdena för textdata gör att det inte är möjligt att förespråka en enskild standard. Dessutom arbetar många forskare redan utifrån standarder som är relevanta för just deras fall, och då kan det vara klokt att se till att utnyttja det faktum att det redan finns information strukturerad på ett standardiserat sätt.
SND:s formulär för att beskriva data bygger till stor del på DDI, men man ska också se till att spara den standardiserade information som forskaren sammanställt i det ursprungliga formatet och gärna ange i datasetets beskrivning att datan följer en viss standard, alternativt flera olika standarder.
Exempel på metadatastandarder för textforskning
TEI Header
TEI Header är del av en mycket större standard, TEI (Text Encoding Initiative), som är ett dataformat snarare än en metadatastandard. TEI Header innehåller metadata som hör till datafilerna i TEI-format. En TEI Header består av en bibliografisk beskrivning av en fil, alltså information som kan användas för att katalogisera eller referera till filen. Dessutom finns information om hur informationen i filen är kodad, till exempel om en text som bygger på en gammal handskrift har fått standardiserad stavning eller inte, med mera. Det finns också möjlighet att baka in metadata i andra format inom TEI Headern, till exempel kan man lägga in Dublin Core-metadata som är kompatibla med de allra flesta system och program. Till sist finns en ändringshistorik som förklarar hur olika versioner av filen har förändrats i relation till varandra.
META-SHARE
META-SHARE är en mycket detaljerad standard för att beskriva resurser som kan användas för att jobba med språkteknologi, alltså till exempel talsyntes, text-till-tal-mjukvara, med mera. Dessa resurser kan vara textbaserade, men META-SHARE kan också användas till ljud, video, program och annat. Ett av målen med META-SHARE är att en dator på egen hand ska kunna avgöra om en resurs beskriven i META-SHARE går att använda för ett visst syfte, därför innehåller META-SHARE detaljerad information om tekniska egenskaper hos filerna som beskrivs.
CMDI
CMDI är också skapat för språkteknologiska resurser. Det bygger på principen att olika organisationer ska kunna använda sina redan existerande standarder och bara mappa dem till en stor uppsättning begrepp som finns i CMDI. På så sätt kan den stora mångfald av standarder som finns och som i viss mån behövs, bli kompatibla med varandra. Det är en bra idé, men uppgiften är väldigt komplex och tungrodd och därför är CMDI inte lätt att arbeta med.
ISO-639
ISO-639 är en uppsättning listor med språknamn kopplade till standardiserade koder på två eller tre bokstäver. De används i väldigt många sammanhang men det finns en del problem åtminstone från en språkvetares perspektiv. Det är till exempel svårt att skilja på olika dialekter eller tidsperioder inom ett visst språk. Dessutom finns det väldigt många små till extremt små språk i världen som inte har någon ISO-kod. ISO-639 täcker alltså inte in alla behov man kan tänkas ha, och det är ett problem som inte är löst än, även om man har gjort olika försök.
Datatyper och dataformat
Forskare som arbetar med text som forskningdata använder många olika mjukvaror, beroende på hur deras forskning ser ut. Vissa program är enkla och allmänt kända, som Word och Excel, medan andra program kan vara egenbyggda och kräva en hel del datorkunskaper. Många forskare arbetar på tvärs över många olika programvaror.
OCR-mjukvara är program som omvandlar analog text till digital text.
Det finns många olika sådana program, vissa specialicerade på handskrift men de flesta för tryckt text. Vad man får ut ur OCR-mjukvara kan variera en del, det kan vara enkel text (TXT eller dylikt), men det kan också vara till exempel något XML-format som innehåller annan information än bara själva bokstäverna. Till exempel kan man få information om var på sidan en viss bokstav finns, så att man kan göra en mer exakt kopia av originaltextens form och inte bara dess innehåll.
Exempel på program som används i textbaserad forskning
Corpus Workbench (CWB) är en uppsättning verktyg för att jobba med stora textkorpusar, alltså sådana som innehåller många miljoner ord. Dessa verktyg är ofta textbaserade, det vill säga de har inget grafiskt gränssnitt utan man behöver använda sig av lite grundläggande kodning för att arbeta på det här sättet. Har man väl vant sig kan man få många nya ingångar till sina texter.
AntConc är ett konkordansverktyg, vilket i princip innebär ett avancerat sökverktyg för att söka i text. Man kan till exempel undersöka i vilka kontexter ett visst ord förekommer eller hur ofta det förekommer tillsammans med ett visst annat ord. Det går också att söka med reguljära uttryck vilket tillåter mycket avancerade sökningar.
MySQL är ett system för att hantera relationsdatabaser. Det finns många andra databassystem men MySQL är väldigt vanligt förekommande. Precis som med Excel så gör sig databaser bra för text där olika delar hör hemma i tydliga kategorier, exempelvis listor på personer, yrken, adresser och olika typer av relationer mellan människorna. Med en sådan databas kan man till exempel ta reda på hur vanligt det är att akademiker på ort A har en viss sorts relation med personer på plats B jämfört med fabriksarbetare.
OpenRefine är ett verktyg för att arbeta med tabellbaserade textdata. Centrala funktioner i OpenRefine kan användas för att städa upp i kaotiska data, exempelvis standardisera olika sätt att ange datum eller dela upp för- och efternamn i olika kolumner. OpenRefine används oftast tillsammans med andra program för att bearbeta data inför ett visst analyssteg, men det går också att använda OpenRefine för avancerade sök- och sorteringsuppgifter, till exempel med reguljära uttryck.
Voyant är en webbtjänst med en uppsättning enkla verktyg för textanalys. Man kan till exempel skapa ordmoln, få ordfrekvenslistor för att se vilka ord som är vanliga och ovanliga i en text, och så vidare.
Oxygen är ett program för att jobba med XML-filer. I språkteknologiska sammanhang är det vanligt med text i XML-baserade format och forskare och forskningsingenjörer arbetar ibland direkt i XML-filerna. Oxygen gör det mycket enklare att arbeta med XML-format jämfört med vanliga textredigeringsprogram.
Filformat
Med de många olika programmen följer också många olika filformat. Varje format ställer sina krav på den som ska kurera och bevara filerna, och komplexitetsnivån kan vara mycket skiftande. De textbaserade formaten går ofta att spara i stort sett som de är, möjligen med lite metadata som förklarar hur de är strukturerade, vilka förkortningar som förekommer och liknande. Textbaserade filer som följer en öppen och väldokumenterad standard behöver knappt ens det.
Helt annorlunda är det med de mer komplexa formaten, till exempel databasformat och GIS-format. Databaser är ju väldigt praktiska för den som har mjukvaran för att komma åt dem, men har man inte den så är de väldigt trögarbetade. Dessutom tenderar databasprogram att uppdateras med tiden och det är inte alltid som de är bakåtkompatibla. Därför kan det vara värt att fundera på om det går att exportera databasen till ett textbaserat format för säkerhets skull. Gör man det bör man också skapa ett databasschema som visar hur man från textfilerna kan återskapa databasen vid behov.
Föredragna format |
Accepterade format |
|
|
Textdokument |
|
|
|
Uppmärkningsspråk |
|
|