Text as research data

Text is one of the most common forms of research data and remains one of our primary ways of communicating and conveying information. While text is perhaps most frequently used in research within the humanities – a classic example being the interview – it is also widely employed in the social sciences, as well as in medical, economic, artistic, and IT-related research.
This page presents information relevant to text-based research. It begins with four case studies illustrating different types of text-based research and research-related activities. These case studies are based on interviews with researchers and staff at a number of institutions with extensive experience of working with text. Each case study is available both as written text and as a video; the content is the same in both formats. Note that the case studies are in Swedish.
Following the case studies, you will find an overview of metadata requirements for text-based research. At the bottom of the page, there is additional information about file formats, data types, and software, which complements what is described in the case studies.
Case studies
The four case studies present examples of research in which text constitutes the main research data. They come from different disciplines and involve diverse kinds of studies, with varying aims and methods. As a result, the research data may appear to differ considerably between the case studies, and their curation places different demands on researchers and research data support staff.
Case 1: Language technology and text processing
Research in language technology aims to simplify and enhance communication between humans and computers, as well as between people. Language technology includes processes and software that allow you to dictate text to a computer without using a keyboard, or that enable a computer to automatically proofread your text. It also makes it possible to converse with someone in another language through automatic translation tools. In short, language technology involves developing tools for machine translation, speech recognition, text analysis, speech synthesis, and electronic dictionaries.
Researchers in language technology often possess extensive programming skills. Those who do not can make use of resources provided by, for example, Researchers working in language technology often have extensive programming skills. Those who do not have such skills may take advantage of the resources made available through, for example, Nationella språkbanken (the Language Bank of Sweden).
In this particular case study, the method involves transforming human-readable text into more machine-friendly formats, such as tables or XML. Because this often entails handling large volumes of text, computers are trained to perform the task automatically. OCR (Optical Character Recognition) software can convert handwritten text into machine-readable form, thereby digitizing the material. Once texts have been digitized and annotated, they can be subjected to advanced analyses, such as generating concordance tables.

Curation
Studies in language technology often rely on specialized research software. Such software is typically developed at universities or research institutes, rather than by major software companies. Because the purpose of the software is research, functionality is often prioritized over user-friendliness. Sometimes the source code is shared via platforms such as GitHub, but not always, and even if the software is available now, there is no guarantee it will remain so in the future. Ideally, therefore, the data should be deposited together with the tool, or at least with instructions for building a tool capable of processing the data.
The data formats used are often open and generally not particularly difficult to interpret. Researchers frequently employ established standards, such as the Text Encoding Initiative (TEI), ISO 639 for languages (see below), or Universal Dependencies for marking syntactic relations.
Annotation is crucial aspect to preserve. Documentation of how annotation has been carried out is essential for assessing the quality of the data and their suitability for different purposes. It is important to specify which standards have been followed, but also which techniques have been used to create the annotation.
Case 2: Comparing African languages
Comparative linguistics focuses on identifying similarities and differences between languages. The research may be based on printed texts or on linguistic material collected through interviews with speakers of different languages. The focus may be on individual words and their pronunciation, or on grammatical constructions within the language.
In this case study, the method involves collecting information by asking informants to translate a number of selected example sentences into their own language and to explain why they choose a particular word or word order in a given context. This process is called “elicitation”, meaning that the researcher prompts the informants to produce specific linguistic content.
The material may consist of thousands of sentences, which must then be annotated so that the researcher can more easily identify interesting aspects of the data. The sentences are transcribed into text, and each word is annotated with information such as morphology and semantics. In the completed file, the researcher can then filter sentences with complex combinations of criteria by importing the Excel file into the OpenRefine tool (see below).
Curation
Since the data are often table-based, it is easy to store them in TSV format. Excel files can also include metadata, added using the plug-in Colectica for Excel. This information can then be stored by using Colectica’s function to create a PDF codebook.
There may also be metadata stored outside the data file itself. Such information may concern the informants and describe, for example, where they grew up, their socioeconomic background, or their parents’ native language. This type of contextual information is important for determining whether a speaker is a reliable source for the language, which may be crucial if two speakers express the same meaning in different ways. It is also valuable to include details about how and when the data collection was carried out, how the speakers were selected, and other relevant circumstances.
Case 3: Distant reading
Distant reading involves analyzing large volumes of text, whether historical or literary. Its opposite, close reading, means stydying a book or a work in detail and carrying out an in-depth textual analysis. With distant reading, the researcher steps back from the text to look for patterns across large bodies of literature at once; for example, comparing different authors, genres, or time periods.
Distant reading may include methods such as:
- text mining – searching large text collections for word frequencies and how they have changed over time. Text mining can also be used to study correlations, such as the historical contexts in which concepts appear (as reflected in the analyzed texts) or which words tend to occur near each other.
- topic modelling – analyzing the thematic structure of texts by studying which concepts are used, in what contexts they occur, and how they relate to one another.
Distant reading with Voyant
In this case study, the researcher uses the web-based text reading and analysis environment Voyant Tools. Voyant Tools provides free software tools available online; all that is needed to get started is one or more texts to examine.
The case study focuses on Bram Stoker’s 1897 novel Dracula. The main interface of Voyant offers several tools simultaneously, many of which are based on word frequencies. Since the most common words are rarely useful for most analyses, a so-called stop word list can be used to specify which words that should be ignored. In this case, the language is English, and the stop word list includes words such as a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, and so on.
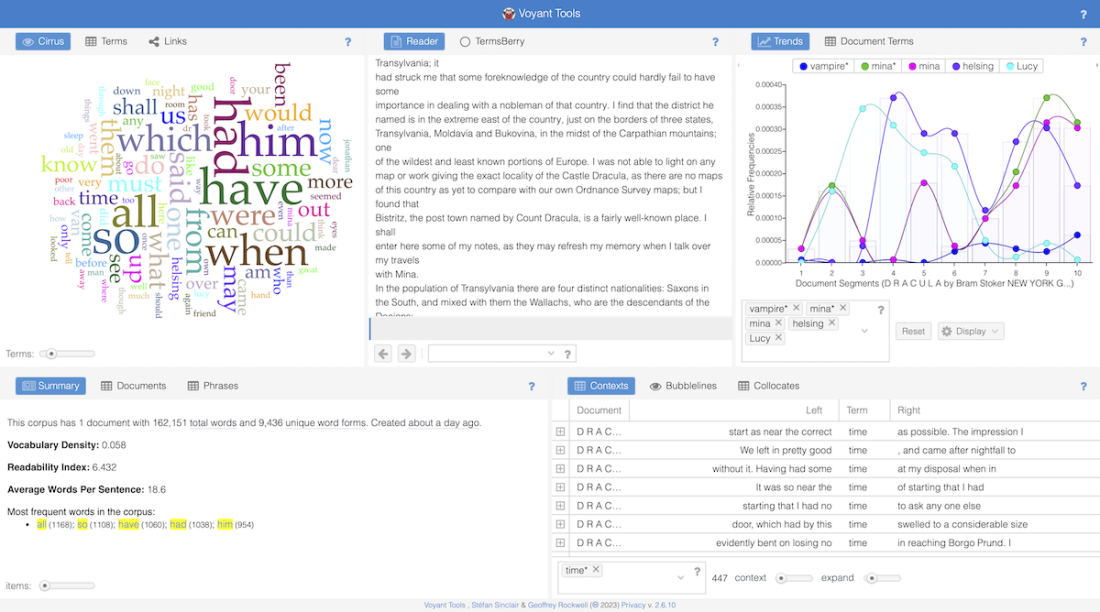
In the top right corner is the Trends tool, which shows how frequently certain words occur in different parts of the text. On the x-axis, the text is divided into ten equally long sections, while the y-axis displays word frequency. Both van Helsing and Lucy are mentioned frequently up to around seven-tenths of the text. There is then a dip, after which van Helsing and Mina increase in frequency, but not Lucy. The word vampire occurs relatively rarely, and almost exclusively in the second half of the novel.
Below Trends is a concordance view showing the contexts in which the word time appears – one of the most frequent words in the text. To the left is a word cloud, which essentially provides a more visually engaging way of displaying a frequency table of the most common words. The larger a word appears in the cloud, the more often it occurs in the text.
Curation
The Voyant tools ignore formatting such as boldface and typeface, so it is best to save texts as plain TXT files. When working with published literature, it is not always necessary or legally possible to make the full texts available. Instead, it may be sufficient to specify exactly which edition has been used, so that others can replicate the analysis.
The stop word list must be preserved, as it directly affects the visualizations. It is also worth considering whether some of the settings used in the Voyant tools should be saved to ensure that the original analysis can be replicated. Researchers using Voyant often do so in an exploratory rather than strictly analytical way and may not always think to save every single setting separately. To preserve this information, the built-in export function can be used; it allows users to export, among other things, a URL that leads back to the exact same view. However, the long-term stability of such URLs is uncertain and cannot be relied upon from a data archiving perspective.
There are many other tools that can also be used for distant reading, such as Python and R. Some researchers even develop their own software or visualizations. Important questions to consider when curating this type of data include:
- How was the material compiled?
- What has been excluded?
- How was it digitized?
- What search parameters were used, and what do they not cover?
- Can the corpus become outdated, and if so, how can it be updated?
Case 4: Student texts
This case study concerns texts written by students as part of their national exams. Such material may be used in research investigating, for example, at what ages children acquire different aspects of language, how social and economic contexts influence language learning, or what challenges immigrant children face compared to those who have grown up in Sweden. Researchers may also use this type of material in pedagogy and educational development; for instance, when evaluating previous exams to inform the design of improved future exams. Since research objectives vary, so do the methods, although the data may nonetheless look quite similar.
Student essays are usually handwritten, and the first step is to digitize them. This can be done manually, by transcribing the text, or with OCR (Optical Character Recognition), which converts the text into a digital file.

Researchers then add metadata directly to the text file, such as exam codes (indicating exactly which examination the students took), an identification numbers for individual students. If the dataset is small, it can be analysed manually; but when there are large volumes of texts, it becomes necessary to develop a tool to assist with analysis. Metadata about the students are also collected in an Excel file, which may include whether the student attended a public or private school, their native language, and other relevant information.
Curation
This type of material can be curated relatively easily. The data are stored in text files, and the metadata in an Excel file. To ensure long-term accessibility, it is advisable to save everything as plain text; that is, TXT format for the essay texts and CSV or TSV for the tables.
However, the coded information in the text files and Excel spreadsheets should be reviewed carefully. The grading system is one example of something that may change over time, meaning that additional information may be required to explain how the system when the student essays were written. In the Excel file, Colectica for Excel can be used to document what all the codes represent. Alternatively, all codes and their explanations can be compiled in a separate text file and deposited together with the data files.
Metadata for text-based research
Text can be used in many different ways and for many different purposes. As a result, metadata for text-based research can be complex. In the interviews conducted for the case studies, researchers mentioned a wide range of objects they considered relevant from a metadata perspective. Depending on how researchers use text in their research, relevant elements may be found at different levels, from low-level features such as words, sentences, or characters, to high-level units such as pages, texts, or files, and at even higher levels such as archives or accessions. It may also be relevant to include information about the individuals who have contributed to the material – the informants.
Metadata at lower levels are often embedded within the files; for example, annotations describing parts of speech or sentence structure. Such metadata should normally not be extracted and stored separately from the text data. High-level object types, however, can sometimes be described outside the data file itself, which can make the data easier to overview and, in some cases, more searchable. For example, metadata about letters in a text collection can add value for users when information such as sender, year, and recipient is included in a catalogue entry, whereas information explaining that the letters contain nouns, verbs, and prepositions adds little additional value.
Information that may be useful for the reuse of text data includes:- subject or research area
- geographical information
- provenance of the text
- time series
- accession number
- metadata about individuals
- metadata on digitization
- technical metadata
- process metadata
- file structure
- archives
- sources of excerpts
- type of record and recorder
- text coordinates
- missing pages
It is helpful for metadata to specify which object types are relevant to the data being described. However, different object types require different forms of description, and the diverse uses of text data make it impossible to recommend a single standard. In many cases, researchers already use standards that are relevant to their particular field or study. In such cases, it is advisable to make use of that existing structured and standardized information.
SND’s data description form is largely based on the DDI metadata standard, but researchers should ensure that any standardized information they have compiled is preserved in its original format. It is also good practice to state in the dataset description which standard or standards the data follow.
Examples of metadata standards for text-based research
TEI Header
The TEI Header is part of the broader Text Encoding Initiative (TEI), which is a data format rather than a metadata standard. The TEI Header contains metadata associated with files in TEI format. It includes a bibliographic description of the file – information that can be used to catalogue or reference it – as well as details about how the text has been encoded. For example, a TEI Header may specify whether text based on a historical manuscript has been standardized in spelling. Other metadata formats, such as Dublin Core (which is compatible with most systems and software), can also be embedded within the TEI Header. Finally, the TEI Header includes a revision history documenting how different versions of the file have changed over time.
META-SHARE
META-SHARE is a highly detailed standard for describing resources used in language technology, such as speech synthesis or text-to-speech systems. These resources may be text-based, but META-SHARE can also be applied to audio, video, software, and other formats. One of its aims is to enable a computer to determine automatically whether a resource described in META-SHARE can be used for a particular purpose. For this reason, META-SHARE includes detailed information about the technical properties of the files being described.
CMDI
CMDI (Component Metadata Infrastructure) is also designed for language technology resources. It is based on the principle that different organizations should be able to continue using their existing standards while mapping them to a common set of concepts defined within CMDI. In this way, the great diversity of existing standards – which is, to some extent, necessary – can be made interoperable. This is a promising approach, but also a complex and demanding one, and as a result CMDI is not always easy to work with.
ISO 639
ISO 639 is a set of lists of language names linked to standardized two- or three-letter codes. These are used in a wide range of contexts, though they have some limitations from a linguistic perspective. For instance, it can be difficult to distinguish between dialects or historical stages of a language, and many small or very small languages around the world do not have ISO codes. ISO 639 therefore does not meet all possible needs, despite ongoing efforts to improve coverage.
Data types and data formats
Researchers working with text as research data use a variety of software tools, depending on the nature of their research. Some programs are simple and widely known, such as Word and Excel, while others may be custom-built and require considerable technical expertise. Many researchers also use several tools in combination.
OCR software (Optical Character Recognition) converts analogue text into digital text. There are many different OCR programs, some specialized in handwriting, though most are designed for printed text. The output can vary; it may be plain text (TXT or similar), or it may be XML that includes additional information beyond the letters themselves – for example, the position of each character on the page, which enables a more accurate reproduction of the original text’s form as well as its content.
Examples of software used in text-based research
Corpus Workbench (CWB) is a suite of tools for working with large text corpora containing many millions of words. These tools are typically text-based and lack a graphical interface, so basic coding skills are required. Once familiar with the system, researchers can gain many new insights into their data.
AntConc is a concordance tool, essentially an advanced search engine for text. It can be used to investigate the contexts in which a word occurs, or how often it appears together with specific other words. Regular expressions can also be used, which allows for very advanced search operations.
MySQL is a system for managing relational databases. There are many other database systems, but MySQL is widely used. Like Excel, databases are well suited for text data where different elements belong to clearly defined categories, such as lists of people, occupations, addresses, or relationships between individuals. A database might, for example, be used to examine how common it is for academics in location A to have professional relationships with people in location B, compared to factory workers.
OpenRefine is a tool for working with table-based text data. Its core functions can be used to clean up messy datasets – for instance, by standardizing date formats or splitting first and last names into separate columns. OpenRefine is most often used in combination with other software for a specific stage of processing or analysis, but it can also perform advanced search and sorting tasks using regular expressions.
Voyant Tools is a web-based service that offers a suite of simple tools for text analysis. It can generate word clouds, produce word frequency lists to identify common and uncommon words in a text, among other features.
Oxygen is a program for working with XML files. XML-based text formats are common in language technology, and researchers or research engineers often work directly within XML. Oxygen makes it much easier to handle XML files than standard text editors.
File formats
The variety of software used in text-based research leads to a wide range of file formats. Each format places different demands on those responsible for curating and preserving the data, and the level of complexity can vary greatly. Text-based formats can often be preserved largely as they are, perhaps with some accompanying metadata explaining their structure, abbreviations, and other key aspects. For files that adhere to an open and well-documented standard, even this may not be necessary.
More complex formats, such as database or GIS formats, pose additional challenges. Databases are very practical for users with access to the necessary software needed but can be difficult to handle without it. Moreover, database software is frequently updated, and older versions are not always backwards-compatible. It may therefore be advisable to export databases to a text-based format as a safeguard. If this is done, a database schema should also be included to show how the database can be reconstructed from the text files if required.
Preferred formats |
Accepted formats |
|
|
Text document |
|
|
|
Markup language |
|
|