Basic principles
The methods you choose to protect the privacy of individuals in research data will depend on several factors. There is no single method that fits all types of research data so the methods must be adapted to each specific case. Below are some general principles and key factors to keep in mind before pseudonymizing your data.1
1. Technical and organizational safeguards
You usually cannot assess how well protected your research data are just by looking at the dataset itself. You must always place your data in a technical and social context. That is, data are stored in IT environments of varying security levels and handled by people with different levels of understanding of and varying attitudes toward what is an acceptable level of privacy and data protection.
Technical safeguards
These are measures to protect participant privacy by regulating the collection, handling, storage, and sharing of research data. While technical safeguards are not a method of pseudonymization, they are crucial for mitigating risks from the environment data exist in. Some examples are encryption, access logging, secure computing environments, multi-factor authentication, access controls, and regular backups.
Organizational safeguards
These may be to train researchers in handling personal data, information security, and data protection laws such as the GDPR. They can also involve establishing clear data protection policies and routines, for example by describing how to handle personal data within a research project in a data management plan. The routines can include limiting access rights, regularly reviewing access permissions (for example when staff leave), and conducting risk assessments to identify and evaluate potential risks for personal data, for instance by adopting incident response plans to quickly and effectively address data breaches that affect personal data.
Local guidelines
To ensure that you follow the best practices in technical and organizational safeguards, it is important to be aware of the conditions at your institution. Check what safeguards are available – such as internal training, secure IT environments, encryption tools, storage solutions, and help from your research data support service.
2. Population and sampling
A major factor that affects the risk of re-identification is the relationship between your target population and the sample you are studying.
Sampling method
One aspect is the sampling method of a research study. All studies have a population that they want to learn more about. Sometimes, all individuals in the population are part of the study, but more commonly, the study deals with a sample of the population. There are three main sampling methods:
Total population sampling
All individuals in the population are included, for example, all residents in Sweden aged 18–85 (≈8.6 million people) or all members of the City Council in Gothenburg (81 individuals). The re-identification risk in a study using total population sampling depends on population size and uniqueness, and what other information you collect about the research participants.
Probability sampling
A random, representative subset of the population is selected to participate in a study. The purpose of probability sampling is often to reflect the variation of the real population in order to draw general conclusions. The size of random samples varies, but they tend to carry lower risks for re-identification than non-random samples (see below), as the real population in population sampling is usually larger and attributes are more evenly distributed. This makes it more difficult to single out an individual from the population.
Non-probability sampling
Participants are not selected at random but based on, for example, their availability to the researcher (convenience sampling) or through referrals from previous research participants (snowball sampling). These sampling methods often lead to an over-representation of certain traits (e.g., profession, location, or age) in the sample. As the distribution of individuals in the sample tends to be uneven, non-probability sampling has an increased risk of re-identification of individuals, with or without additional data sources.
A large population generally reduces the probability of re-identifying individuals within a sample. When more individuals share common traits, it is more difficult to identify a particular individual in the sample. However, if you are studying a population with specific attributes, for example a rare profession, some information about the research participants is already known. This increases the re-identification risk compared to if you were studying a larger population with less or no known information about the research participants. In Sweden, variables like gender, age, education, and location are often openly accessible in public data sources. By matching those variables with observations in the data, it can be fairly easy to identify an individual. You should be aware of what variables the data contain, and if there are any openly accessible data sources that can be linked to the participants.
If the population you are studying is, for example, members of the City Council in Gothenburg in 2024, we already have a fair bit of knowledge about the study participants. We can quite easily link information in the research data to other openly accessible data sources and connect responses in the material to individuals. However, if you are instead interested in a population containing all persons between the ages of 18 and 85 in Sweden, we know considerably less about the potential study participants. This decreases the risk of re-identification of individuals in the research data. Even if it is possible to identify an individual in the sample, it is more difficult to find out who is part of the sample and to connect responses to an individual.
Study design
Study design is another factor that affects the re-identification risk. These are some common study designs and their associated risks:
Cross-sectional studies
Cross-sectional studies study a unique population at a unique point in time, with the purpose of providing a snapshot of a phenomenon at a given time. These have a lower re-identification risk than longitudinal studies (see below), as the research participants do not need to be contacted again, so no directly identifying information, like home or e-mail address, has to be retained in the dataset.
Longitudinal studies
Longitudinal studies follow participants of the same population over a longer time, with the purpose of studying changes and patterns over time. There is a higher risk of re-identification in longitudinal studies or panels than in cross-sectional studies, as longitudinal studies have to retain directly identifying information in order to fulfil the research purpose, as data need to be collected on several occasions.
Experimental studies
Study designs with experiment and control groups used to compare differences between groups of a population are common in some scientific fields. The groups can be randomly selected or selected based on particular attributes. If the groups are assigned based on identifiable attributes like occupation or hometown, this may increase the re-identification risk if information about the attributes can be found in additional data sources.
3. The content of the research data
The most significant risk factor that you assess and manage as a researcher is the content of your research data. This includes types of identifiers in the data and how sensitive the information is. It may not be obvious which type of variables or which combination of information poses a risk for re-identification, or which types of information may be sensitive. To make a risk assessment of the data you work with, you will need to take a wider perspective and include factors beyond the actual dataset.
How sensitive is the information in the research data?
Apart from the fact that sensitive personal data are subject to specific requirements, sensitivity should also be assessed based on the potential harm or damage disclosure of the information could cause. Beyond legally defined “sensitive personal data”, such as ethnic origin, political opinions, sexual orientation, and health, this might include information of a sensitive nature that is embarrassing, taboo, or even illegal, and that could cause serious harm for the individual if it is disclosed. If the data you study contain this type of information, you need to take extra care in how the data are handled and shared.
List direct and indirect identifiers
One of the first things you do when assessing re-identification risk is to list which variables may pose a risk. Start by identifying obvious and potential identifiers in the data. Assess whether these variables should be classified as direct identifiers or indirect identifiers and/or key variables. Then think about which combinations of variables could potentially be used to identify an individual.
Information that does not directly identify an individual but can still be used to link information to participants is called indirect identifiers or key variables. Key variables tend to be easily accessible and widely known information and are often used as background variables. Some examples are age, gender, and place of residence, but which variables can be key variables varies between studies.
The Finnish Social Science Archive has compiled a list of potential direct and indirect identifiers.
By combining gender, date of birth, and postal area code, a well-known study by Latanya Sweeney, “Simple Demographics Often Identify People Uniquely”, showed that 87% of the US population could be re-identified using additional data sources. Be careful with identifying variables in the data that could be linked to other data sources.
In The Observatory of Humanity, you can test how many steps are needed to single out an individual from a population.
Identify unique observations and outliers
It is not uncommon for datasets to contain observations with unique or uncommon combinations of attributes. An observation is unique if it stands out from the studied population. An outlier is an extreme observation that is set apart from the rest of the data. These unique observations and outliers have a higher risk of re-identification because they stand out.
Examples include:
- a rare profession or job role
- living in a small community
- very high or low income
- very low or high age
- very low or high BMI
- rare medical conditions
- a family with many children
- a rare political view or hobby
- an ethnic origin that is uncommon in Sweden
A common method for identifying unique observations is to combine various indirect identifiers in your data to view the distribution between groups. In quantitative data, a simple histogram showing the distribution of, for example, gender, age, and municipality, can quickly visualize whether any individuals stand out. Another method is by visualizing two variables in a scatterplot to reveal whether a young person in a sample has an unusually high income for their age bracket (see below).
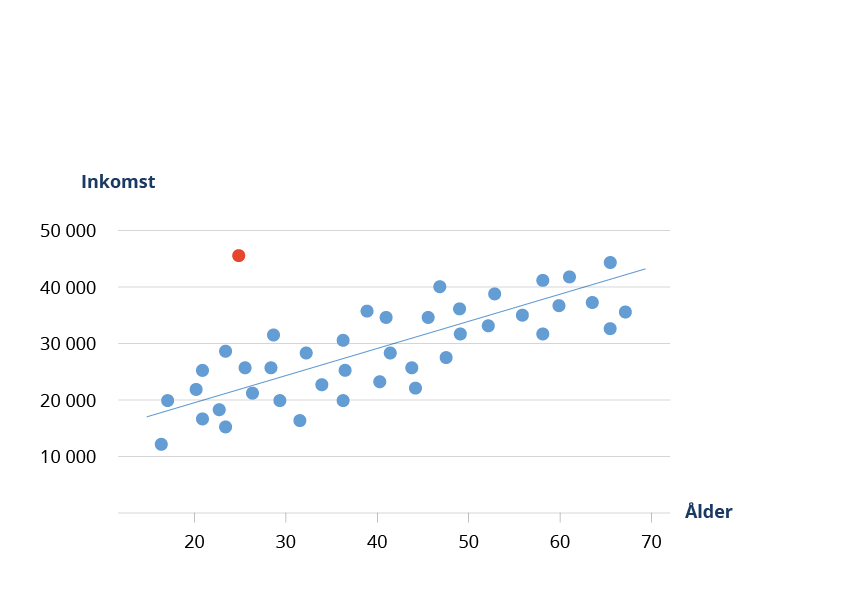
Can you identify a third party in your data?
Another common but less obvious problem is information about third parties. A third party could be identified by information disclosed in the data, which may also lead to the identification of the research participant, or respondent. If a respondent discloses information about their relatives, colleagues, or other information that can indirectly be linked back to the respondent, they may inadvertently identify themselves. It is also important to make sure that respondents do not disclose any information that may identify a third party. This problem is especially common for studies with free-text responses, where the respondents are not limited to given alternatives, but can elaborate as they choose on a particular question or phenomenon.
An example: A respondent mentions that they often visit their 92-year-old father in a particular nursing home in a sparsely populated municipality, because they live only a few minutes away.
Are there any hidden or overlooked metadata?
Metadata are data that describe data. Digitally collected data often contain metadata that can be difficult to identify or assess. Hidden metadata are data that do not belong to the actual content of the studied and analyzed research data but were collected as a by-product. Some examples are the IP address of a user account replying to a questionnaire, GPS coordinates from a smartphone used for an online survey, times and/or dates when a study or survey was begun or completed, the serial number of an x-ray image, instrument settings, source code, and temporary usernames.
Hidden metadata can be just as identifying as background variables as your dataset and are often overlooked during pseudonymization. Be aware of and identify what metadata your data collection tools – for example, a survey tool or other external service – produce, so you can minimize the re-identification risk.
Test your pseudonymization
It may be difficult to assess how well you protect your data. Ask yourself and test:
- Can individuals still be distinguished by combining variables? Meaning, are there still individuals with unique attributes after you have pseudonymized the data?
- Can information from external data sources be used to connect observations or combinations of variables in the data and that way identify individuals?
- How likely is it that someone could attribute specific information in the data to an individual?
4. The age of the dataset
The age of a dataset matters to the re-identification risk. The older the dataset, the harder it tends to be to identify an individual from the sample, as information like age, education, address, occupation, or income changes over time. Note that if your data are so old that the research participants are deceased, GDPR no longer applies.
However, be aware that older datasets may be part of ongoing longitudinal or panel studies. It is not uncommon for this type of sub-studies or panel waves to have a code key or participant IDs that can re-identify individuals in a current dataset.
5. The linkability of the dataset
Another important but perhaps less obvious safeguard is to consider how easily your pseudonymized data could be linked to other available data sources. In short, linkability means that information about an individual in your pseudonymized data can be linked to another data source where the individual’s identity is not protected. The more additional data sources exist about the studied population, the greater the risk of re-identification. Access to additional data is key to further evaluations about safeguards or other statistical methods for pseudonymization.
Accessible additional data sources may include:
- unpseudonymized original versions of a dataset
- data from official registers
- information that can be found through digital search engines
- information in social media
- people's personal knowledge.
6. Balancing usefulness and privacy
Pseudonymizing or anonymizing data inevitably results in some loss of information, which can affect the usefulness of the data to you as a researcher, as well as to potential secondary users. The ideal is to make minimal changes to the data to make them pseudonymized or anonymized, for example by removing direct identifiers and/or recoding indirect identifiers, but this is not always easy – especially with qualitative data or free-text responses.
When the information loss would be too great for the research purpose, it may be more effective to focus on technical and organizational safeguards to protect the privacy of the research participants. By restricting access to the dataset, limiting how it is stored, shared, and for what purposes it may be used, or by defining in what form it may be used and published, you can prevent many privacy risks. However, this may become an administrative burden to you as a researcher, as well as to secondary users who want to reuse the dataset.
Quantitative data are often easier to pseudonymize. Some examples are by recoding numerical variables such as age into broad ranges or recoding geographical variables such as municipality to county – this can be done without losing too much information, while still protecting the privacy of the research participants. Qualitative data or data from free-text responses require more nuanced judgement and are harder to anonymize without significant information loss.
As a researcher, you must weigh participant privacy against the usefulness of the data – both for your own research and for future potential reuse.
7. Documenting the research process
You should always document the decisions and measures you take to protect research data. One way is by using a standard template to document what risk-mitigating strategies and data transformations you have applied. The Finnish Social Science Data Archive (FSD) has created a useful anonymization plan template that shows a structured documentation of your decisions and the rationale behind them.
Good documentation is essential not just for future reference, but also in the event of a privacy or data protection incident or audit. Being able to demonstrate your decisions and actions can be crucial if legal issues should arise.
References
1. This content is partly based on information from Data Management Guidelines [Online]. Tampere: Finnish Social Science Data Archive [distributor and producer]. < https://www.fsd.tuni.fi/en/services/data-management-guidelines/anonymisation-and-identifiers/#bases-of-anonymisation; (retrieved on 07.15.2025).