Grundprinciper
Vilka metoder du som forskare väljer att använda för att skydda forskningspersoners integritet i forskningsdata kan bero på flera olika faktorer. Det finns ingen enskild metod som passar för alla typer av forskningsdata utan metoderna behöver anpassas från fall till fall. Nedan listar vi några allmänna principer och faktorer som du bör känna till innan du börjar pseudonymisera forskningsdata.1
1. Tekniska och organisatoriska skyddsåtgärder
I de flesta fall kommer du inte kunna avgöra hur skyddade dina forskningsdata är bara genom att titta på datamängden i sig. Du behöver alltid sätta dina forskningsdata i ett tekniskt och socialt sammanhang. Det vill säga, de sparas och lagras i mer eller mindre säkra IT-miljöer och hanteras av människor med varierande förståelse av och inställning till vilken nivå av säkerhet och integritetsskyddande åtgärder som är godtagbar.
Tekniska skyddsåtgärder
Tekniska skyddsåtgärder handlar om åtgärder för att skydda forskningspersoners integritet genom att reglera insamling, hantering, lagring och delning av forskningsdata. Den här typen av åtgärder är inte en metod för pseudonymisering, men väl så viktiga för att hantera den riskmiljö som forskningsdata existerar i. Några exempel på tekniska skyddsåtgärder är kryptering, loggning, användning av säkra beräkningsmiljöer, multifaktorautentisering, andra åtkomstkontroller samt regelbunden säkerhetskopiering.
Organisatoriska skyddsåtgärder
Organisatoriska skyddsåtgärder kan till exempel vara att genomföra regelbundna utbildningar för forskare om hantering av personuppgifter, informationssäkerhet och dataskyddslagar som GDPR. Det kan också handla om att utveckla och implementera tydliga dataskyddspolicyer och rutiner, till exempel inom ramen för en datahanteringsplan, som beskriver hur personuppgifter ska hanteras inom forskningsprojektet. Detta kan inkludera begränsning av behörigheter och införande av rutiner för hur en verksamhet ska säkerställa att behörigheter regelbundet gås igenom och plockas bort, exempelvis när en anställd avslutar sin anställning. Det är också viktigt att genomföra riskbedömningar för att identifiera och värdera potentiella risker för personuppgifter, till exempel att ta fram incidenthanteringsplaner för att snabbt och effektivt kunna reagera på säkerhetsincidenter som påverkar personuppgifter.
Lokala bestämmelser
För att säkerställa att du följer bästa praxis inom tekniska och organisatoriska skyddsåtgärder är det viktigt att du tar reda på hur förutsättningarna ser ut på just ditt lärosäte. Undersök till exempel möjligheten till internutbildningar och hur du på bästa sätt kan arbeta med tillgängliga IT-miljöer, krypterings- och lagringslösningar samt utnyttja lärosätets forskningsdatastöd.
2. Population och urval
En av de mest grundläggande faktorerna som påverkar risken för återidentifiering av enskilda individer i forskningsdata är förhållandet mellan populationen du är intresserad av och urvalet du studerar.
Urvalsmetod
En viktig aspekt har att göra med forskningsstudiens urvalsmetod. Alla studier har en tänkt population som man vill få kunskap om. Ibland ingår alla individer i studien, men oftast behöver det göras ett urval så att bara en delmängd ur populationen ingår i studien. Det finns tre breda urvalsmetoder:
Totalurval
Ett totalurval är ett urval där samtliga individer i en population ingår i studien. Ett totalurval kan till exempel vara alla individer i Sverige mellan 18 och 85 år (cirka 8,6 miljoner individer). Men det kan också vara alla kommunfullmäktigeledamöter i Göteborgs kommun (81 individer). Risken för återidentifiering i en studie som använder totalurval beror på populationens storlek, hur unik den population du väljer att studera är samt vilken annan information du samlar in om forskningspersonerna.
Sannolikhetsurval
I ett sannolikhetsurval, eller slumpmässigt urval, slumpas en representativ delmängd ur den totala populationen fram och bjuds in att delta i en studie. Syftet med slumpmässiga urval är ofta att spegla variationen som finns i den verkliga populationen för att kunna dra generella slutsatser. Storleken på slumpmässiga urval varierar men risken för återidentifiering i ett slumpmässigt urval är i regel mindre än i ett icke-slumpmässigt urval (se nedan). Det beror på att den verkliga populationen i ett slumpmässigt urval ofta är större eller på att spridningen av egenskaper och attribut är mer jämnt fördelad. Därmed kan det bli svårare att urskilja en enskild individ ur mängden.
Icke-sannolikhetsurval
I ett icke-sannolikhetsurval slumpas inte forskningsdeltagare fram ur populationen utan väljs exempelvis ut genom hur lättillgängliga de är för forskaren (bekvämlighetsurval) eller genom att tidigare forskningsdeltagare rekommenderar andra som också kan delta (snöbollsurval). Dessa typer av urval leder ofta till urval där individer med en specifik egenskap, till exempel yrke, boendeort eller ålder, är överrepresenterade. Eftersom fördelningen av individer i ett icke-sannolikhetsbaserat urval ofta är ojämnt fördelad kan risken för återidentifiering, med eller utan hjälp av kompletterande datakällor, öka.
Med en stor population minskar sannolikheten att en enskild individ kan urskiljas i urvalet. Detta beror på att antalet individer som delar samma egenskaper i en stor population i regel är större än i en liten population. Det blir då svårare att urskilja en specifik individ i mängden. Om man däremot är intresserad av en population med specifika attribut, till exempel ett visst yrke, innebär det att det redan på förhand finns information om forskningspersonerna i urvalet. Det innebär att risken för återidentifiering är större än om du hade varit intresserad av en större population där du på förhand har mindre eller ingen information om forskningspersonernas egenskaper. Kön, ålder, utbildningsnivå och bostadsort är exempel på variabler som finns öppet tillgängliga i andra publika datakällor i Sverige. Genom att matcha sådana variabler med observationerna i data kan det vara relativt enkelt att särskilja en enskild individ. Du behöver därför vara särskilt medveten om vilken typ av variabler som data innehåller och hur tillgången och länkbarheten till kompletterande och öppet tillgängliga datakällor ser ut.
Om den population du är intresserad av exempelvis är kommunfullmäktigeledamöter i Göteborg 2024 vet vi på förhand ganska mycket om deltagarna i undersökningen. Vi kan ganska enkelt ringa in och länka uppgifter i forskningsdata till andra öppet tillgängliga datakällor för att koppla respondenternas svar till enskilda individer. Om den population du är intresserad av i stället består av alla personer i Sverige mellan 18 och 85 år vet vi på förhand väldigt lite om vilka personer som potentiellt kan delta i din undersökning. Då minskar risken att specifika individer kan identifieras i forskningsdata. Även om det skulle vara möjligt blir det svårare att ringa in vilka som ingår i urvalet och kräver mer att försöka lista ut vilka svar som tillhör en viss individ.
Studiedesign
Även studiedesignen kan påverka risken för återidentifiering. Nedan listas några vanligt förekommande studiedesigner och associerade risker för återidentifiering.
Tvärsnittsstudier
Tvärsnittsstudier används för att studera en unik population vid ett unikt tillfälle. Syftet är att ge en ögonblicksbild av ett fenomen vid en given tidpunkt. Risken för återidentifiering är i regel lägre i en tvärsnittsstudie än i en longitudinell studie (se nedan) eftersom forskningspersonerna inte behöver kontaktas igen och det därför inte behöver sparas någon direkt identifierande information som exempelvis postadress eller e-postadress i datamängden.
Longitudinella studier
Longitudinella studier används för att studera en och samma population över tid. Syftet med den här typen av studier är att undersöka förändringar och mönster över tid. Risken för återidentifiering i longitudinella studier eller paneler är i regel större än i tvärsnittsstudier eftersom man behöver spara direkt identifierande information för att forskningsstudien ska kunna genomföras, då data behöver samlas in vid flera tillfällen.
Experimentella studier
Inom vissa forskningsfält är det vanligt att använda sig av studiedesigner med experiment- och kontrollgrupper för att jämföra skillnader mellan olika grupper inom en population. Dessa grupper kan antingen vara slumpvis indelade eller indelade efter specifika attribut. Om gruppindelningen baseras på specifika attribut kan det innebära en ökad risk för återidentifiering om information om attributen finns tillgänglig i kompletterande datakällor, till exempel yrke eller bostadsort.
3. Innehållet i forskningsdata
Den kanske mest påtagliga riskfaktorn som du som forskare behöver hantera är innehållet i forskningsdata. Det handlar både om vilken typ av identifierare som data innehåller och om hur känslig informationen är. Samtidigt är det inte alltid uppenbart vilken typ av variabler eller kombinationer av information som utgör en risk. Det är inte heller alltid självklart vilken typ av information som faktiskt kan anses vara känslig. För att kunna göra en riskbedömning av de data du arbetar med behöver du ofta lyfta blicken och inkludera externa faktorer som ligger utanför själva datamängden.
Hur känslig är informationen i forskningsdata?
Utöver det faktum att känsliga personuppgifter omfattas av särskilda bestämmelser bör känsligheten i data också bedömas utifrån den skada eller men som informationen i data kan orsaka forskningspersonerna. Förutom etniskt ursprung, politiska åsikter, sexuell läggning och hälsa finns det annan integritetskänslig information som kan vara pinsam, tabubelagd eller till och med brottslig och som kan vara till stor skada för en enskild om den kommer ut. Om data innehåller den här typen av uppgifter bör du vara extra försiktig med hur de hanteras och eventuellt delas vidare.
Lista direkta och indirekta identifierare
Något av det första du bör göra när du bedömer risken för återidentifiering är att lista vilka variabler som kan utgöra en risk. Börja med att lista uppenbara och potentiella identifierare i dina data. Bedöm om variablerna ska klassas som direkta identifierare eller indirekta identifierare och/eller nyckelvariabler. Skapa dig därefter en uppfattning om vilka kombinationer av variabler som potentiellt skulle kunna användas för att särskilja en enskild individ.
Uppgifter som inte är direkt identifierande men som ändå kan användas för att koppla ihop uppgifter med objekt kallas för indirekta identifierare eller nyckelvariabler. Nyckelvariablerna utgörs vanligtvis av lättillgänglig och allmänt känd information och används ofta som bakgrundsvariabler. Exempel på vanligt förekommande nyckelvariabler är ålder, kön och bostadsort, men vilka variabler som kan tjäna som nyckelvariabler varierar mellan undersökningar. Här finns en sammanställning av potentiella direkt och indirekt identifierande variabler.
Genom att kombinera kön, födelsedatum och postnummer visade en amerikansk studie av Latanya Sweeney att det gick att direkt identifiera 87 % av den amerikanska befolkningen med hjälp av kompletterande datakällor. Var därför extra varsam med identifierare i dina data som går att länka till andra datakällor. Här kan du själv prova hur många steg som behövs för att särskilja en person i en population.
Identifiera unika observationer och outliers
Det är inte ovanligt att datamängder innehåller observationer med helt unika eller ovanliga kombinationer av attribut. En observation är unik om den särskiljer sig från mängden i populationen du är intresserad av. En så kallad outlier är en extrem observation som avviker markant från resten av dina data. Särskilt unika observationer och outliers löper i många fall större risk för återidentifiering eftersom de sticker ut i en datamängd.
Några exempel på information som gör att individer sticker ut i en population kan vara:
- Ett ovanligt yrke eller en ovanlig befattning
- Boende i kommun/ort med väldigt få invånare
- Mycket hög eller låg inkomst
- Mycket låg eller hög ålder
- Mycket lågt eller högt BMI
- En ovanlig sjukdom
- Stort antal barn i hushållet
- En ovanligt förekommande politisk åsikt eller hobby
- Ett etniskt ursprung som är ovanligt i Sverige.
Ett vanligt sätt att identifiera särskilt unika observationer är att kombinera olika indirekt identifierande variabler i dina data för att se hur fördelningen mellan olika grupper ser ut. I kvantitativa data kan ett enkelt histogram som exempelvis visar fördelningen av kön, ålder och boendekommun snabbt visualisera huruvida enskilda individer sticker ut. Ett annat sätt är att visualisera två variabler samtidigt i ett spridningsdiagram för att till exempel identifiera om en yngre person i datasetet tjänar ovanligt mycket för sin ålder (se exempeldiagram).
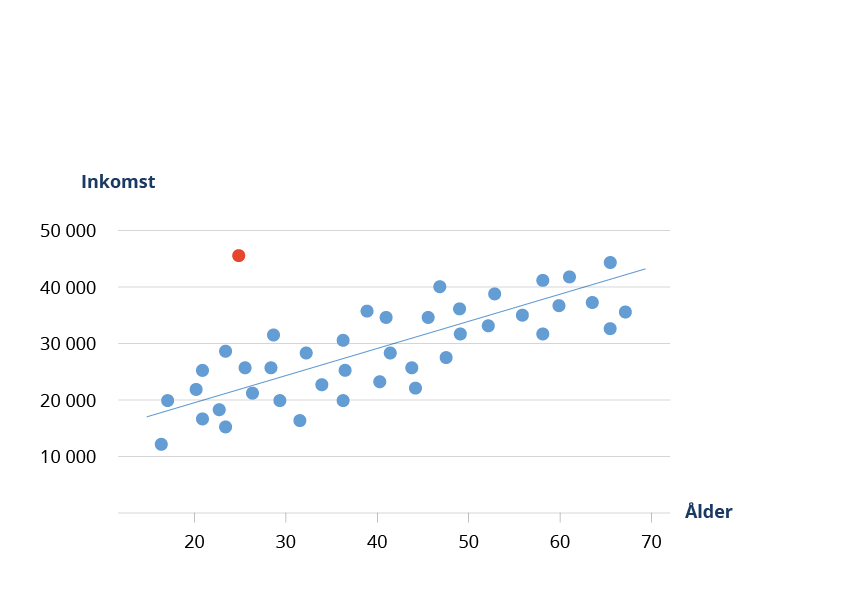
Går det att identifiera en tredje part i dina data?
Ett annat vanligt förekommande men mindre uppenbart problem är information om tredje part. En tredje parts identitet skulle kunna röjas genom information som framkommer i data, vilket också skulle kunna bidra till att forskningspersonens identitet röjs. Om en respondent exempelvis lämnar information om släktingar, arbetskollegor eller andra uppgifter som indirekt går att länka tillbaka till respondenten går det i vissa fall att identifiera en person. Det är också viktigt att se till att forskningspersonen inte lämnar någon information som kan avslöja en tredje parts identitet. Den här typen av problem är speciellt vanligt förekommande i studier med fritextsvar där respondenten inte är bunden till svarsalternativ utan fritt får resonera kring en specifik fråga eller ett fenomen. Ett exempel kan vara en respondent som anger att hen ofta hälsar på sin 92-åriga pappa som bor på ett visst ålderdomshem i en viss glesbefolkad kommun, eftersom det endast ligger ett stenkast från den egna bostaden.
Finns det gömda eller glömda metadata?
Metadata är lite förenklat data som beskriver data. Digitalt insamlade data innehåller ofta någon typ av metadata som kan vara svår att identifiera eller bedöma. Gömda metadata avser data som inte tillhör innehållet i de forskningsdata som studeras och analyseras. Ofta handlar det om data som ”kommer på köpet” i samband med en datainsamling. Det kan vara allt från en IP-adress kopplad till ett användarkonto som används för att fylla i en enkät, geografiska koordinater från en smartphone som använts för att besvara en webbenkät, klockslag och/eller datum då en studie eller enkät påbörjades eller avslutades, till ett serienummer på en röntgenbild, instrumentinställningar, källkod, tillfälliga användarnamn och liknande.
Gömda metadata kan vara lika identifierande som olika typer av bakgrundsvariabler i en datamängd. Det är dock inte ovanligt att den här typen av information glöms bort eller förbises i samband med pseudonymiseringsprocesser. Därför är det viktigt att identifiera och se över vilken typ av metadata som en datainsamling (till exempel ett visst enkätverktyg eller annan extern tjänst) producerar för att minska risken för återidentifiering.
Testa hur väl du har pseudonymiserat
Det är inte alltid lätt att utvärdera hur väl du har skyddat dina data. Några grundläggande frågor som du bör ställa och även testa är följande:
- Kan du särskilja enskilda individer i data genom att kombinera olika variabler? Det vill säga, finns det fortfarande personer med helt unika attribut efter att du pseudonymiserat dina data?
- Går det att koppla samman observationer eller kombinationer av variabler i dina data med hjälp av andra datakällor och på så sätt identifiera enskilda individer?
- Med hur stor sannolikhet kan du dra slutsatsen att specifik information kan tillskrivas en unik individ i dina data?
4. Datamängdens ålder
Hur gammal en datamängd är spelar roll för risken för återidentifiering. Ju äldre forskningsdata är, desto svårare är det i regel att identifiera en person eftersom information om exempelvis ålder, utbildning, bostadsort, yrke eller inkomst varierar över tid. Notera att om dina data är så pass gamla att forskningspersonerna avlidit gäller inte längre GDPR.
Var dock uppmärksam på att det kan finnas äldre separata datamängder som är en del av en pågående longitudinell eller panelstudie. Det är inte ovanligt att den här typen av delstudier eller panelvågor har någon form av kodnyckel eller löpnummer som gör att forskningspersoner kan återidentifieras i en aktuell datamängd.
5. Datamängdens länkbarhet
En annan viktig men kanske mindre uppenbar skyddsåtgärd är att du skapar dig en uppfattning om dina datas länkbarhet till andra tillgängliga datakällor. Länkbarhet innebär lite förenklat att information om en individ i dina pseudonymiserade data går att koppla till en annan datakälla där individens identitet inte är skyddad. Risken för återidentifiering eller bakvägsidentifiering är större ju fler kompletterande datakällor det finns om den population du vill undersöka. Tillgången till kompletterande data är därför avgörande för dina vidare bedömningar kring skyddsåtgärder eller andra statistiska metoder för pseudonymisering.
Tillgängliga datakällor kan exempelvis vara:
- ett originaldataset som inte är pseudonymiserat
- registerdata från myndigheter
- information som går att hitta genom digitala söktjänster
- information i sociala medier
- personers egen kännedom.
6. Balansen mellan användbarhet och integritet
Pseudonymisering eller anonymisering av data innebär alltid någon typ av informationsförlust. Det påverkar i sin tur datas användbarhet både för dig som forskare och för potentiella sekundäranvändare. I idealfallet behöver endast en liten del av dina data ändras för att räknas som pseudonymiserade eller anonymiserade, exempelvis genom att du raderar direkta och/eller kodar om indirekta identifierare. Det är dock ofta lättare sagt än gjort.
I de fall där informationsförlusten riskerar att bli alltför stor kan en strategi vara att fokusera på tekniska och organisatoriska skyddsåtgärder snarare än statistiska metoder för att säkerställa integriteten hos forskningspersonerna. Genom att reglera tillgången till datamängden, hur den lagras, sprids och i vilka syften den används samt i vilken form den får användas och publiceras kan du i många fall förebygga flera integritetsrisker. Samtidigt kan detta innebära en administrativ börda både för dig som forskare och för sekundäranvändare som vill använda dessa data.
I många fall är kvantitativa data enklare att pseudonymisera. Numeriska variabler som ålder kan kodas om till bredare ålderskategorier och geografiska variabler som kommun kan kodas om till län utan att dina data förlorar alltför mycket information, samtidigt som forskningspersonernas integritetsskydd ökar kraftigt. I kvalitativa data och data som bygger på fritextfrågor kan processen vara svårare och risken för informationsförlust är större.
Som forskare måste du ta ställning till balansen mellan forskningspersonernas integritet och dina datas användbarhet, både för dina egna forskningssyften och för potentiella framtida sekundäranvändare.
7. Dokumentation av forskningsprocessen
För att dokumentera de steg du tar i din forskningsprocess bör du alltid dokumentera vilka åtgärder du genomför för att skydda forskningsdata. Ett sätt kan vara att använda en mall där du som forskare dokumenterar vilka riskmitigerande åtgärder och förändringar av data du gör. Här är ett exempel på en sådan mall från Finlands samhällsvetenskapliga dataarkiv (FSD).
Dokumentationen är inte bara viktig för att komma ihåg vad du gjort med dina data, den är också viktig vid en eventuell integritets- eller dataskyddsincident eller granskning. Att kunna styrka de överväganden och åtgärder du har genomfört kan vara avgörande för om du som forskare skulle råka ut för juridiska påföljder.
Referenser
1.Innehållet på denna sida bygger delvis på information från Data Management Guidelines [Online]. Tampere: Finnish Social Science Data Archive [distributor and producer]. < https://www.fsd.tuni.fi/en/services/data-management-guidelines/anonymisation-and-identifiers/#bases-of-anonymisation; (citerad 05.02.2024).